 Throwable具有 Exception和 Error 两个子类
Throwable具有 Exception和 Error 两个子类Java集合
Collection接口
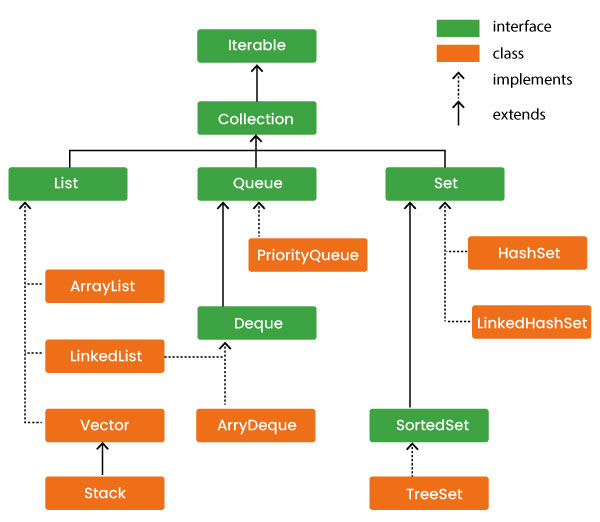
List
ArrayList
基本内容
- 可以允许null值
- 内存是连续的,节省内存空间。
- 插入时间复杂度:插在队头O(n)因为要把后面的元素都往后移动一位;插在队尾,如果不需要扩容,则是 O(1),如果需要扩容则先需要 O(n)把原来的 ArryList复制一遍,再执行O(1)的插入操作。 插在队中间,O(n).
- 删除时间复杂度:与插入的时间复杂度相对应。
- 并非线程安全。
底层实现
- 由动态数组实现,随机访问某个节点,只需要计算它的地址值,因此随机访问O(1). 实现了RandomAccess这一个标识借口。
- 如果没有指定初始容量,那么默认初始容量为0,第一次添加元素时,容量变成10. 每次动态扩容,容量变成原来的1.5倍。
ArrayList与 Array 的区别
- ArrayList可以动态扩容;Array则不行,它的长度是固定的,并且需要在初始化数组的时候就指定长度
- ArrayList支持泛型
- ArrayList只支持对象,对于基本数据类型则需要使用它们的包装类如Integer, Double。Array支持基本数据类型和对象。
LinkedList
底层实现
- 双向链表实现。在头部/尾部进行插入/删除的时间复杂度均为O(1)
- 不支持随机访问。每次访问指定元素的时间复杂度为O(n)
- 性能不如ArrayList, 在实际开发中基本不会用到。
- 线程不安全。
- 允许null值
- 除了数据之外还要存指针,所以占用空间比LinkedList大。
HashMap
实现原理
- 哈希表+链表/红黑树实现。解决哈希冲突的方法有 chaining/probing,一般使用chaining.
- 哈希值如何计算?拿到key的hashcode()。将原 hashcode和hashcode右移16位的值进行异或运算。
| |
- 计算数组下标。hash&(length-1),相当于hash%length. 二进制运算比取模运算更快。
- 如果遇到碰撞,就在链表或红黑树中找是否存在该key,如果存在则直接替换值,如果不存在,就加到里面去。链表长度为 8,并且哈希表长度大于64时,升级成红黑树。
- 红黑树节点数少于6时,变回链表。
- 初始容量16,负载因子0.75,扩容至原来的两倍。
- 并非线程安全。扩容的时候可能会造成链表成环。
时间复杂度
理想情况下,HashMap 的插入、删除和查找操作平均时间复杂度都是 O (1)。
如果转成红黑树,操作的时间复杂度会稳定在 O (log n)
持久化
参考:小林 coding
参考视频
AOF
Append Ony File,是一个文本文件,因此较大。 当客户端发起一个写请求时,Redis 主线程首先在内存中执行写操作,接着将这个写命令同步到磁盘中的 AOF 日志中。
Virtualization
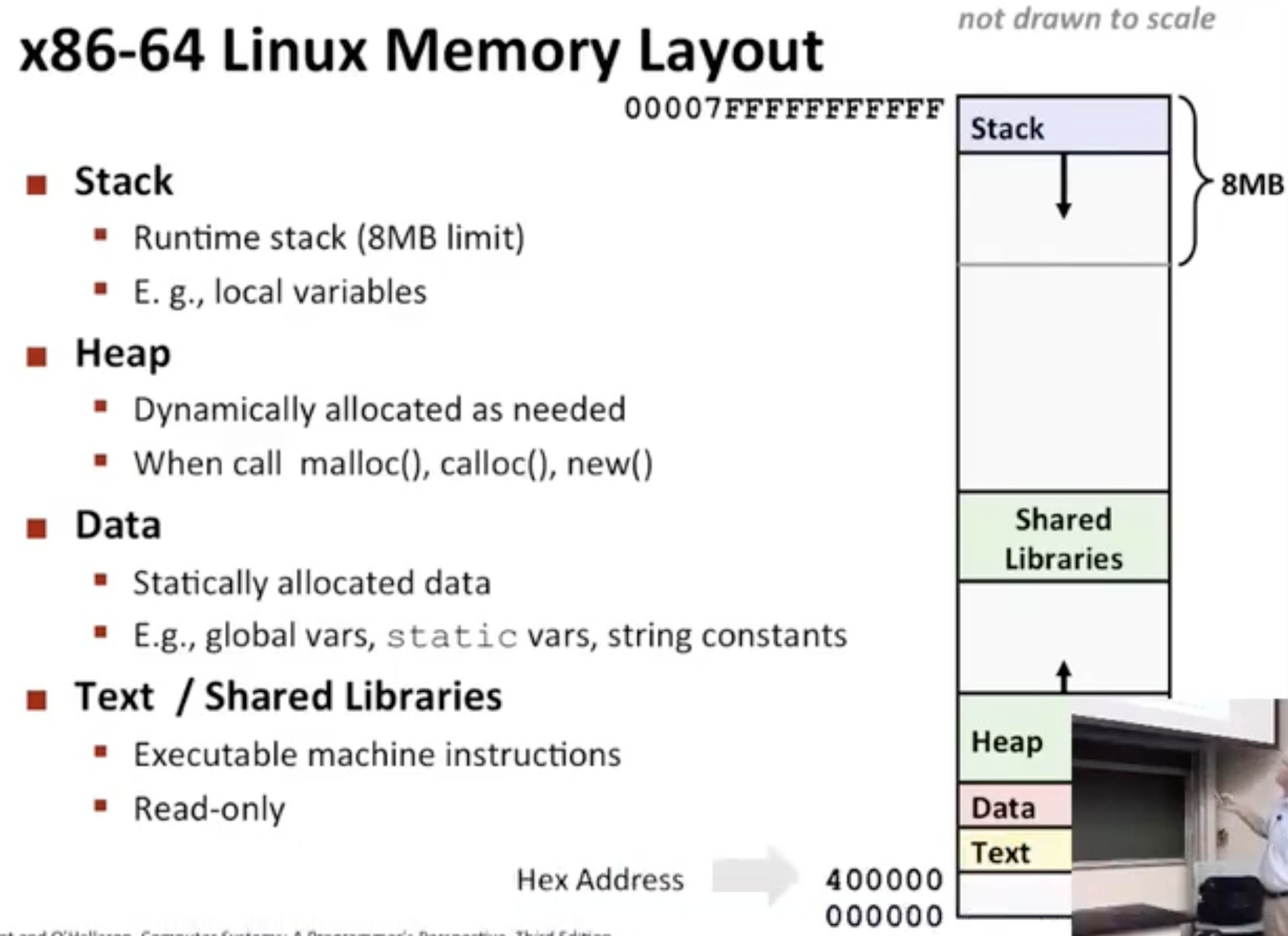
问题排查
ThreadLocal&线程池
参考:JavaGuide
ThreadLocal
Thread类里面有一个变量threadLocals,可以视为一个 HashMap,用来存放线程私有的内容。
| |
ThreadLocal类里面有一个instance 方法 set,实际上是把内容存在threadLocals里面。key是该ThreadLocal对象自己。