索引
聚簇索引、二级索引
聚簇索引
InnoDB中,每个表都有一个聚簇索引,它决定着数据在磁盘上存储的物理顺序。
- 如果有 primary key, 即为聚簇索引
- 如果没有 primary key, 选择一个唯一的非空索引作为聚簇索引
- 如果还是没有,InnoDB隐式地创建一个自增列作为聚簇索引
B+ Tree
InnoDB在默认情况下,聚簇索引和二级索引都使用 B+ Tree存储。
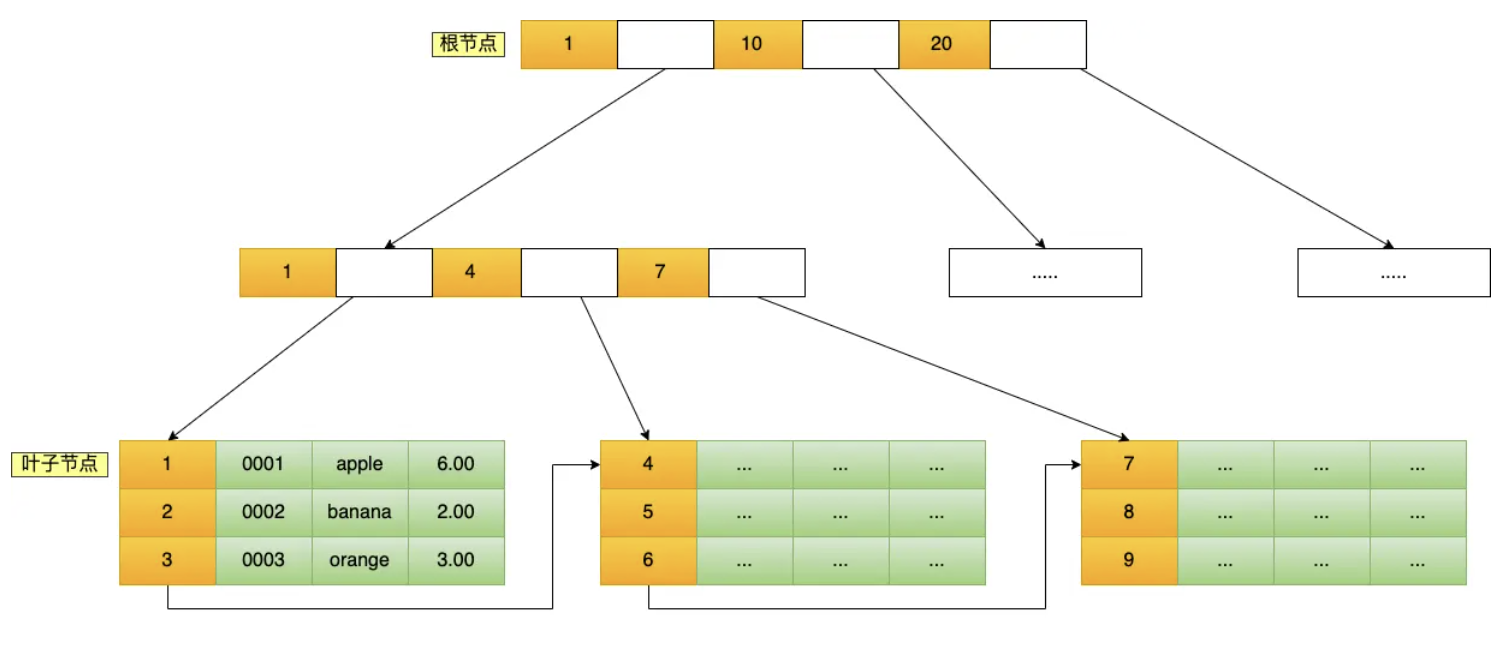 B+树只有叶子节点才会存放数据,每个叶子节点里的数据按主键顺序排序,并且相邻的叶子节点用双向指针连接。非叶子节点存放索引和指向子节点的指针。
B+树只有叶子节点才会存放数据,每个叶子节点里的数据按主键顺序排序,并且相邻的叶子节点用双向指针连接。非叶子节点存放索引和指向子节点的指针。
索引和数据都存储在硬盘,所以每访问一个节点,都是一次磁盘 IO。B+树存储千万级别的数据只需要 3-4 层,也就是 3-4 次磁盘 IO。
B+树相比B树的优点:
- B+树的非叶子节点可以存储更多的键值和指针,降低树的高度,减少磁盘 I/O 次数。
- 范围查找时,B树需要遍历整颗树;B+树只需要遍历叶子结点的链表。
- 顺序访问方便。
B+树相比二叉树的优点: B+树中,一个节点最多有m个孩子,m的值通常为几百到几千。搜索的时间复杂度为O(logN),底数为 m.
二级索引
聚簇索引的叶子节点存实际数据,二级索引的叶子节点存主键值。
如果根据二级索引查询,并且需要查的数据不止主键,那么就需要回表,也就是查询两次 B+树。如果查的数据只有主键,那么不需要回表。
主键索引、唯一索引、前缀索引
| |
一个表可以有多个唯一索引,必须建在 UNIQUE 字段之上。
普通索引:不要求字段为 PRIMARY 或 UNIQUE
前缀索引:对字符类型字段的前几个字符建立索引,目的是减少索引占用空间。字符类型:char, varchar, binary, varbinary.
binary类型是用来存储字节字符串的, 可以用来存储图片、视频等二进制数据。
单列索引、复合索引
复合索引也叫联合索引,指的是在多个字段上创建索引。唯一值多的列通常放在最前面。
最左匹配
最左匹配:对 (col1, col2, col3) 创建联合索引。在 B+树的存储中,是先按col1排序,如果col1相同就再按col2排序,以此类推。
可以使用的查询条件:
col1 = ?
col2 = ? AND col1 = ? (优化器会进行优化)
col1 = ? AND col2 = ? AND col3 = ?
不能使用的查询条件:
col2 = ?(没有从最左列 col1 开始)
col3 = ?(没有从最左列 col1 开始)
联合索引能否用于范围查询?
可以,但范围查询列后面的列无法使用索引。例如,索引是 (col1, col2, col3),查询 WHERE col1 = 1 AND col2 > 2 AND col3 = 3,col3 无法使用索引。
因为在col1 = 1 AND col2 > 2找出来的记录中,col3是无序的。比如col1=1, col2=3, col3=5和 col1=1, col2=4,col3=2这两条记录。
如何判断联合索引是否生效?
| |
查看 key_len为 4,代表一个 int,也就是说salary的索引并没有生效
SELECT * FROM users WHERE age >= 25 and salary=50000;这个语句中,哪个字段用到了联合索引?
都用到了。虽然age>25的部分,salary是无序的。但是当age=25时,查到的salary是有序的,所以此时可以减小扫描范围,联合索引生效。
SELECT * FROM users WHERE age BETWEEN 20 AND 30 and salary=50000;这个语句中,哪个字段用到了联合索引?
MySQL中,BETWEEN代表20<=age<=30,所以这两个字段都用到了联合索引。
SELECT * FROM users WHERE name like ‘j%’ and salary=50000;这个语句中,联合索引(name, salary)哪个字段用到了联合索引?
都用到了。name like ‘j%‘会匹配所有以j开头的字符串。其中所有 name为j的记录中,salary 是有序的。
索引下推
| |
没有索引下推时,是先根据department_id查到所有 10 部门的员工记录,然后回表去获得完整的行数据,再筛选hire_date符合条件的记录。
有索引下推功能时,在通过索引dept_hire_date_idx扫描过程中直接应用hire_date BETWEEN ‘2024-01-01’ AND ‘2024-12-31’这个条件。这意味着对于每个满足department_id = 10的索引项,如果它的hire_date不在指定范围内,则不会进行回表操作,从而减少了不必要的磁盘I/O和内存消耗。
索引区分度
使用联合索引时,把索引区分度大的字段放在前面。索引区分度=unique的column个数/总column个数
索引失效
- 左/左右模糊匹配:因为索引B+树是按索引值排序的,只有右模糊匹配才能利用索引定位到一个范围。
- 对索引使用函数,比如where length(name)=6。但是可以对函数计算的结果建立索引。
- 对索引进行表达式计算。比如where age+1=30不行,但是where age=30-1可以。这是因为innoDB并没有给age+1建立索引。
- 隐式类型转换。MySQL会把字符串自动转换为整型。如果存的是int,where 输入是 varchar,那么是对输入值调用 cast 函数,索引不会失效;如果存的是 varchar,where 输入是 int,那么相当于对索引调用函数,全表扫描。
- 联合索引不符合最左匹配。
- Where 条件 1 Or 条件 2,但是只有其中一个字段在索引里。
慢查询
页面加载过慢、接口压测响应时间超过1s
- SkyWalking可以查看每个接口的响应时间,可以定位到具体是哪个 SQL 语句执行得太慢
- MYSQL自带慢日志
| |
索引原因
使用EXPLAIN命令弄清楚原因。
- select_type(查询类型):
- SIMPLE: 简单SELECT查询(不包含子查询或UNION)
- type
- system: 表里只有一条记录
- const: 主键/唯一索引,查到唯一一条记录
- eq_ref: 多表关联时,使用主键或唯一索引关联
- ref: 使用普通索引等值查询
- extra
- using index: 覆盖索引
- using index condition: 索引下推,在引擎层就过滤。
- using where: 需要回表
- using temporary: 需要用到额外表。(GROUP BY 与 ORDER BY 的列不同/GROUP BY 使用了未建立索引的列)
- using filesort: 额外排序操作。(ORDER BY 使用了未建立索引的列/ORDER BY 与 WHERE 使用的索引不同/多表连接查询时排序字段不在驱动表)
连接数过小
客户端与服务端之间的连接数量太少,导致部分SQL语句阻塞。
MySQL服务器的默认最大连接数为100,可以更改到500;
客户端应用存在一个连接池,每次拿里面的连接出来复用。改一下ORM的连接池最大数量即可。
Buffer Pool太小
查看buffer pool的缓存命中率,一般情况下在99%以上。
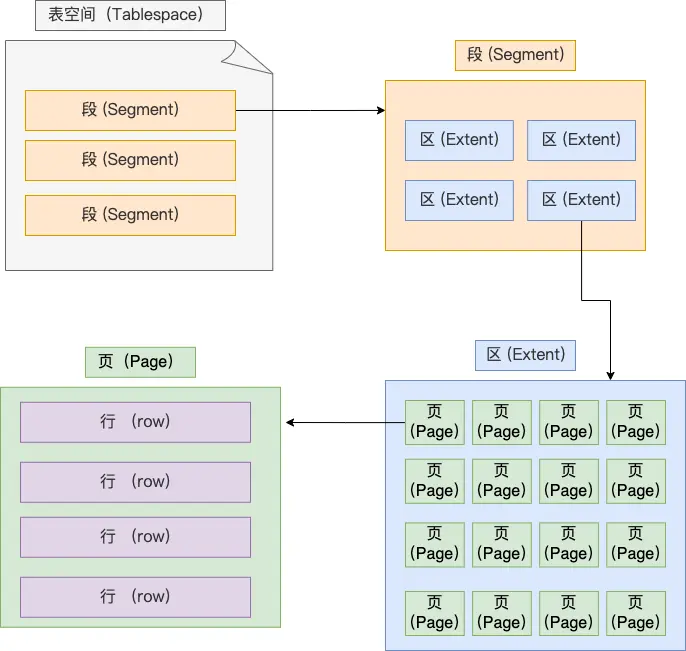
表空间
.frm 文件存放表结构定义;
.ibd 文件保存表数据
页分裂
主键 ID 非自增,为什么会有页分裂的可能?