垃圾回收
参考: 深入理解Java虚拟机 , 极致八股文之JVM垃圾回收器G1&ZGC详解
对象已死?
引用计数算法
| |
缺点:这两个对象互相引用,导致他们的 reference counting 始终不能为 0,无法被回收。
可达性分析算法
从GC Root出发,根据引用关系向下搜索,标记所有可以达到的对象。搜索过程中走过的路径叫做“引用链”。
🌟可作为GC Root的对象:
- 虚拟机栈栈帧中局部变量表中的对象(方法参数、临时变量、实例方法的this对象)
- 方法区中类静态变量
- 方法区中常量引用的对象
- 本地方法栈中 Native方法引用的对象
- 所有被 synchronized 持有的对象
- Java 虚拟机内部的引用:基本数据类型对应的 Class对象、常驻的异常对象、系统类加载器
即使被标记为不可达,也不是一定会被回收。
引用的概念
一般只用强引用和软引用,因为软引用可以加速JVM垃圾回收的速度。
- 强引用:Object obj=new Object(),垃圾回收器绝对不会回收它。
- 软引用:有用,但非必需。只要内存还够,就不会回收它。如果内存快满了,就回收它。
- 弱引用:只能生存到下一次垃圾回收。无论当前内存是否充足,都会回收它。
弱引用是通过java.lang.ref.WeakReference
类来创建的。 - 虚引用:仅持有虚引用的对象相当于没有任何引用。虚引用只是用来跟踪该对象的引用情况的,因为每次回收对象内存时,如果它有虚引用,JVM会把虚引用加入引用队列,由此可知它将要被垃圾回收。
回收类和常量
(在方法区中)回收类需要满足三个条件
- 该类的所有实例都被回收
- 加载它的类回收器被回收
- 该类对应的java.lang.Class对象没有在任何地方被引用,无法在任何地方通过反射访问该类的方法。
回收常量
分代收集理论
假说:
- 大部分对象都是朝生夕死的
- 熬过越多次垃圾收集过程的对象就越难以消亡
部分收集:
- 新生代收集(Minor GC/Young GC):目标只是新生代
- 老年代收集(Major GC/Old GC)
- 混合收集(Mixed GC):收集整个新生代和部分老年代
整堆收集:回收整个堆和方法区。
标记-清除算法
首先标记不需要被回收的对象,接着把没有被标记的对象全部回收。
缺点:效率低下、会产生大量不连续的内存碎片。
标记-复制算法
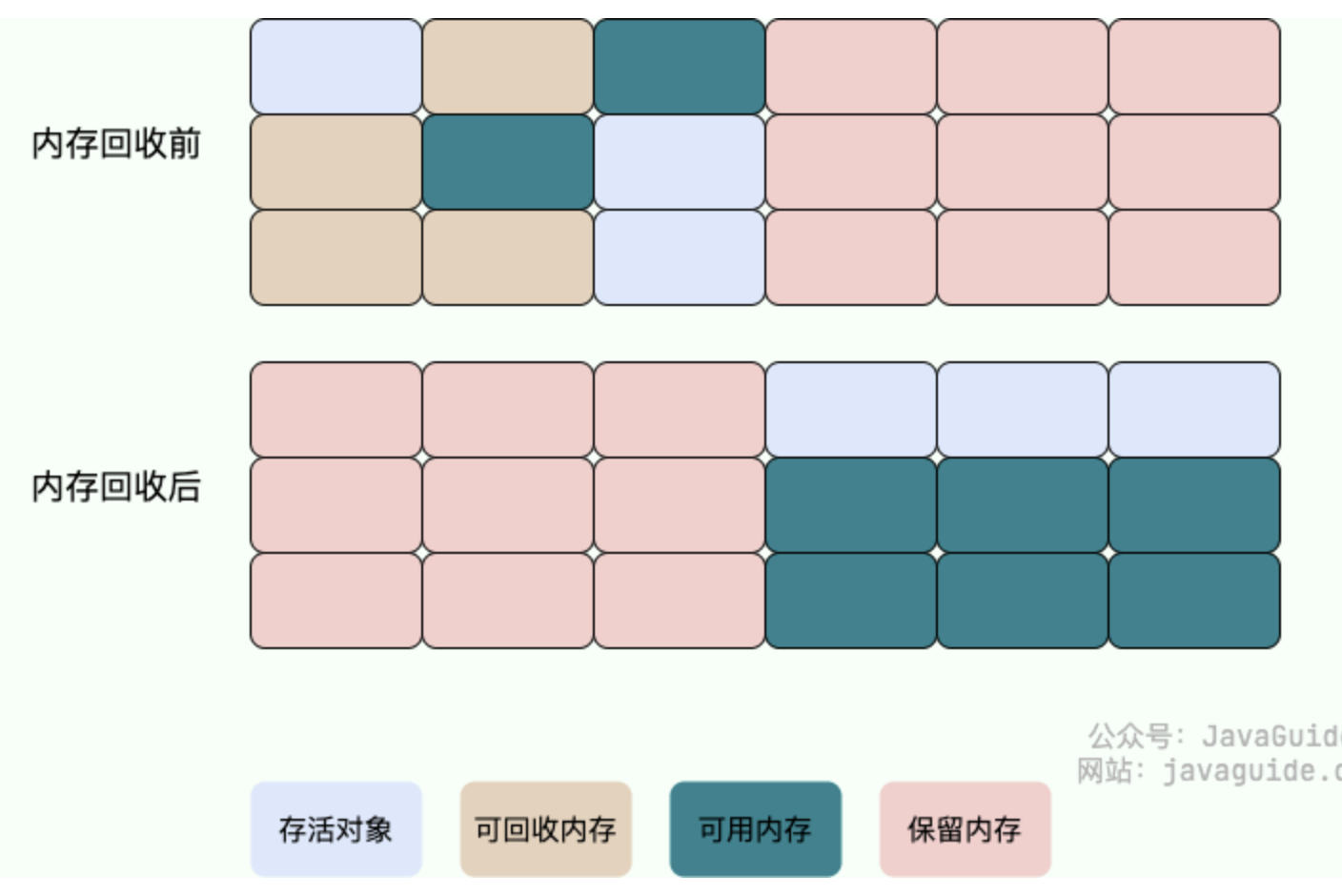 每次只用内存的一半。标记完之后,把存活的对象移动到另一半内存去,然后把之前那半内存全部回收。
每次只用内存的一半。标记完之后,把存活的对象移动到另一半内存去,然后把之前那半内存全部回收。
现代商用虚拟机多采用这种算法来回收新生代。由于对象朝生夕死的特点,新生代中分为Eden, Survivor1, survivor2,大小比例为8:1:1。每次只使用Eden和一个 Survivor,等到发生垃圾回收,把 Eden里面和Survivor里面存货的对象全部复制到另一个Survivor中。
缺点:可用内存空间变小。
标记-整理算法
适合老年代。与标记-清除算法的不同仅在于,该算法在回收垃圾之后,把剩余的对象移动到内存连续的空间。
经典垃圾收集器
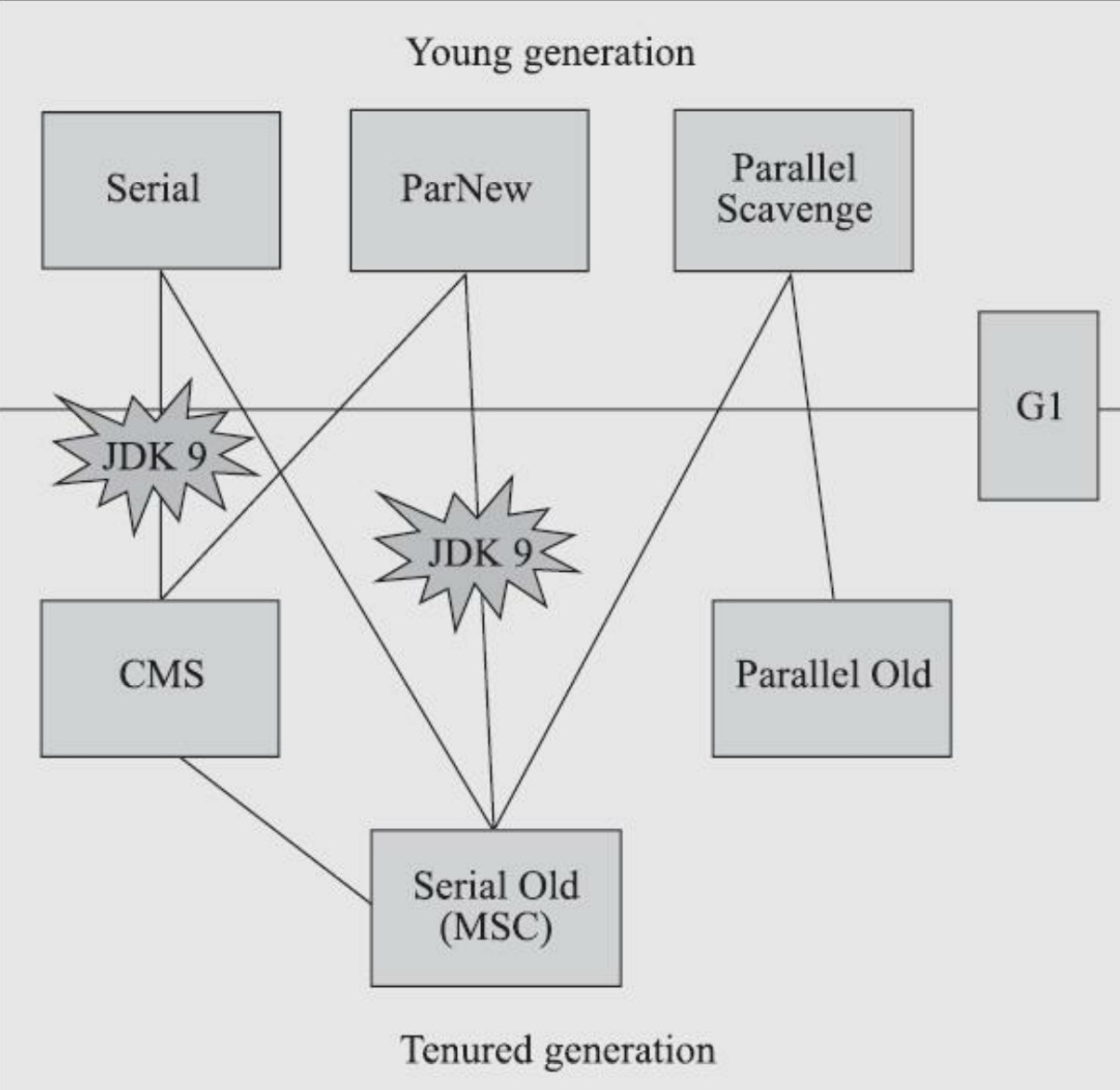
Serial收集器
历史悠久的单线程收集器,并且它执行的时候会暂停其它所有用户线程。新生代采用标记-复制,老年代采用标记-整理。
ParNew收集器
Serial收集器的多线程版本。
Parallel Scavenge收集器
关注吞吐量。JDK1.8 默认使用的是 Parallel Scavenge + Parallel Old。
吞吐量=运行用户代码时间/(运行用户代码时间+运行垃圾收集时间)
-XX:MaxGCPauseMillis:控制最大垃圾收集停顿时间。
降低停顿时间,通过减小新生代的内存大小。但这样垃圾回收会更频繁,吞吐量也会降低。
-XX:GCTimeRatio:设置吞吐量大小。
一个大于0小于100的整数,代表垃圾收集占用时间的百分比。
Serial Old收集器
Serial 收集器的老年代版本。
Parallel Old收集器
Parallel Scavenge收集器的老年代版本。
CMS收集器
目标是让回收停顿时间最短。采用标记-清除算法,是Hotspot第一款做到并发的垃圾收集器。
- 初始标记🌟:标记与root直接相连的对象,停顿一下。
- 并发标记:并发地标记所有对象,不需要停顿用户线程。
- 重新标记🌟:并发标记的时候,用户线程可能队某些对象进行了更改,所以这里补充一次,会停顿稍长时间。
- 并发清除:不需要停顿用户线程,但是会产生内存碎片。
G1 收集器(Garbage First)
面向服务器,同时满足高吞吐量和短停顿时间;JDK9开始的默认垃圾收集器。整体来看,采用标记-整理算法;局部来看,采用标记-复制算法,没有内存碎片。
与 CMS 的不同在于,G1建立起了可预测停顿模型,也就是在M毫秒的时间片之内,处理垃圾收集的时间大概率不超过N毫秒。
-XX:MaxGCPauseMillis=50
采用 Mixed GC 模式,可以把堆内存的任何部分组成一个回收集。它把 Java 堆分成许多个大小相等的region,每个 region 可以去扮演新生代或者老年代。
G1跟踪每个region中垃圾的价值(回收所获得的内存大小&回收所需时间的经验值),维护一个优先级列表,根据用户所设定的允许停顿时间,去优先处理价值大的 region。
- 初始标记🌟:短暂停顿,仅标记GC Root直接相连的对象
- 并发标记:与应用并发地执行,标记所有可达对象
- 最终标记🌟:短暂停顿,处理上一阶段结束后发生变化的对象
- 筛选回收🌟:暂停用户线程,多线程并行执行回收。对每个 region 的回收价值和回收成本进行排序,根据用户期望的停顿时间来制定回收计划。把仍然存活的region复制到另一块大region 中,清除之前的那块大region。
ZGC收集器
在对吞吐量影响不太大的前提下,实现在任意堆内存大小下,都可以把垃圾收集的停顿时间限制在十毫秒以内的低延迟。
 把堆内存分成很多个不同大小的 page
把堆内存分成很多个不同大小的 page
面试问题
- G1的垃圾回收过程(伴随minorGC进行的初始标记、并发标记、重新标记、筛选回收)
- G1是怎么实现MaxGCPauseMillis的
- STW是如何实现的
- fullGC都GC哪些区域
- 为什么java8用元空间替换了永久代,增大永久代大小配置不行吗
- OOM、CPU 100% 如何排查