Java Collections
Collection Interface
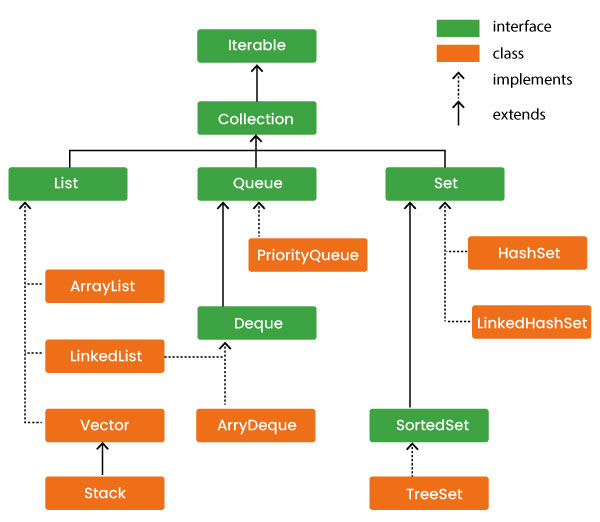
List
ArrayList
Basic Content
- Allows null values
- Memory is contiguous, saving memory space.
- Insertion time complexity: Inserting at the head is O(n) because all subsequent elements need to be shifted one position back; inserting at the tail is O(1) if no expansion is needed, but if expansion is required, it first needs O(n) to copy the original ArrayList, then performs O(1) insertion operation. Inserting in the middle is O(n).
- Deletion time complexity: Corresponds to insertion time complexity.
- Not thread-safe.
Underlying Implementation
- Implemented by dynamic array, random access to any node only requires calculating its address value, so random access is O(1). Implements the RandomAccess marker interface.
- If no initial capacity is specified, the default initial capacity is 0. When adding the first element, capacity becomes 10. Each dynamic expansion increases capacity to 1.5 times the original.
Difference Between ArrayList and Array
- ArrayList can dynamically expand; Array cannot, its length is fixed and must be specified during array initialization
- ArrayList supports generics
- ArrayList only supports objects; for primitive data types, their wrapper classes like Integer, Double must be used. Array supports both primitive data types and objects.
LinkedList
Underlying Implementation
- Implemented with doubly linked list. Insertion/deletion at head/tail has O(1) time complexity
- Does not support random access. Time complexity for accessing a specific element is O(n)
- Performance is inferior to ArrayList, rarely used in actual development.
- Not thread-safe.
- Allows null values
- Besides data, it also stores pointers, so it occupies more space than ArrayList.
HashMap
Implementation Principle
- Implemented with hash table + linked list/red-black tree. Methods to resolve hash collisions include chaining/probing, generally using chaining.
- How is hash value calculated? Get the key’s hashcode(). XOR the original hashcode with the value of hashcode right-shifted by 16 bits.
| |
- Calculate array index. hash&(length-1), equivalent to hash%length. Binary operations are faster than modulo operations.
- If collision occurs, search in the linked list or red-black tree to see if the key exists. If it exists, directly replace the value; if not, add it. When linked list length reaches 8 and hash table length is greater than 64, upgrade to red-black tree.
- When red-black tree node count is less than 6, convert back to linked list.
- Initial capacity 16, load factor 0.75, expand to twice the original size.
- Not thread-safe. During expansion, it may cause linked list cycles.
Time Complexity
Ideally, HashMap’s insertion, deletion, and search operations have an average time complexity of O(1).
If converted to red-black tree, operation time complexity stabilizes at O(log n)
Expansion
- Bucket has only one node: directly rehash and move to new hash table.
- Linked list. Traverse the linked list, rehash each element. Their new position is either the original index or original index + original capacity. So it’s equivalent to splitting into two linked lists.
- Red-black tree. Treat as linked list. When nodes reach 6, degrade to linked list.
Thread Unsafe
put operation is not atomic. If two threads calculate the same bucket index for two elements and concurrently insert values into the hash table, one insertion operation may be overwritten by another.
When HashMap is expanding and another thread wants to perform a put operation, does it insert into the new table or the old table?
If expansion is not yet complete: The new thread’s put operation will attempt to operate on the old table. This is because during expansion, the old table is still accessible, and when the new thread executes put, it will first check the old table’s status. If it discovers expansion is in progress, it will try to assist with the expansion operation (assist in migrating elements). After assisting with part of the expansion work, it continues with the put operation, but ultimately still calculates the insertion position based on the old table.
If expansion is complete: The new thread’s put operation will operate on the new table. Because after expansion completion, HashMap’s internal table reference already points to the new array, and subsequent operations will all execute based on the new array.
ConcurrentHashMap
- Generally uses CAS for handling single key-value pairs
- When handling linked lists or red-black trees, applies synchronized to their head nodes. But other threads can freely modify other buckets.
- HashMap’s key and value can both be null. But ConcurrentHashMap’s key and value cannot be null.
- ConcurrentHashMap doesn’t allow null values mainly because its design philosophy is to provide strong consistency in high-concurrency scenarios. If null values were allowed, handling concurrent reads and writes would become very complex, making it difficult to determine whether a key’s absence means it truly doesn’t exist or its value is null, easily causing data inconsistency issues, so it simply doesn’t allow them.
Why Red-Black Tree Instead of AVL Tree
AVL Tree: The height difference between left and right subtrees of any subtree is at most 1.
Each insertion/deletion of nodes may require rotation operations, affecting performance.
Red-Black Tree: Root node is black. Red means the node’s parent is black.
On any path from root to leaf nodes, the number of black nodes is equal.
Black node’s children are red or null.