Distributed Systems
RPC Basics
protobuf IDL
- Define the
.protofile: define Request/Response formats and function signatures. - Protobuf generates
CalculatorStubautomatically.1 2 3 4 5 6 7 8channel = grpc.insecure_channel("server-ip:port") # Client stub (a local proxy for server-side methods) stub = CalculatorStub(channel) # Call Stub.Add as if it were a local function request = AddRequest(num1=2, num2=3) response = stub.Add(request) - Implement the actual logic for
addon the server side.
Semantics
At most once
- Have reply: the server executed exactly once.
- No reply: the server executed once or zero times.
At least once
- Have reply: the server executed at least once.
- No reply: the server executed zero, one, or multiple times.
- This is fine for read-only operations, or idempotent operations (e.g., the Map phase in MapReduce).
Primary-Backup
CAP
- Consistent views of the data at each node
- Availability of the data at each node
- Tolerance to network partitions
BASE
- Basically Available: the system remains usable, but may occasionally fail or respond more slowly.
- Soft state: state may change without external input (due to background synchronization).
- Eventual consistency: reads may not be latest immediately, but all replicas converge eventually.
Normal Flow
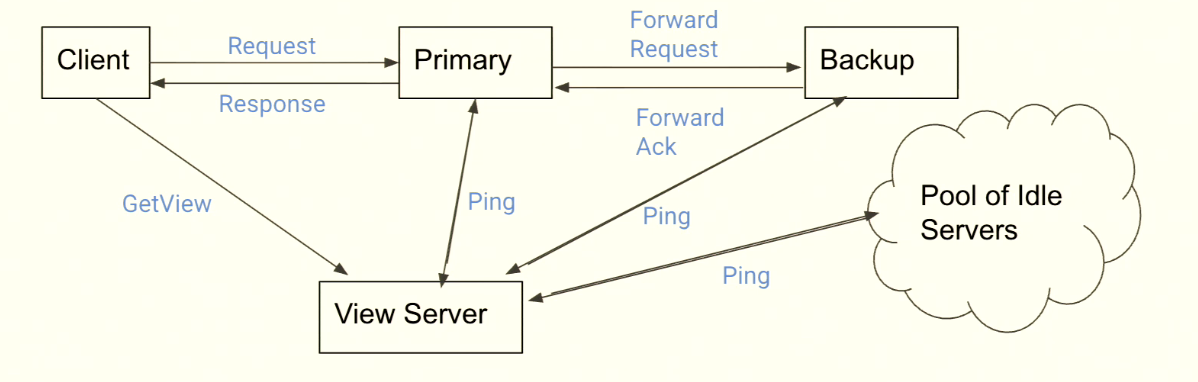
Client sends request: the client sends requests (e.g., Put) only to the Primary.
Primary orders requests: after receiving requests, the Primary decides execution order (e.g., A before B).
Forward: the Primary forwards the operation to the Backup.
Backup executes: Backup executes (or logs) the operation and replies “ready” to Primary after catching up.
Primary executes and replies: only after receiving Backup’s ack can Primary execute and reply success to the Client.
View Server
ViewServer maintains the current view.
A view consists of:
ViewNumPrimaryBackup
All servers periodically ping ViewServer with Ping(ViewNum). If ViewServer detects Primary failure, it announces a new view and promotes Backup to new Primary.
State Machine Replication
$$\text{Same initial state} + \text{same input commands} + \text{same execution order} = \text{same final state}$$
Failure Recovery
- ViewServer detects a dead server and creates a new view, then returns that view in subsequent
ViewReply. - When a server receives
ViewReply, and finds itself Primary with a changed Backup, it does:- State Transfer: package all in-memory key-values and send RPC to the new Backup.
- Wait for Ack: before receiving ack from new Backup, Primary cannot process any client request.
- Only after receiving Backup ack, Primary starts pinging with the new
viewNum, indicating view transition is complete. - State transfer is needed only when Backup changes. Transfer the whole
AMOApplication.
- Scenario: client sends request to Primary A but times out, queries ViewServer for latest full view, then retries to the new Primary.
Rule 1: Forward Before Execute
- After receiving a request, Primary forwards to Backup first and lets Backup execute.
- Then Primary executes and sends ack to client.
- Primary forwarding must use a timer.
If not: Primary might execute and ack client, but forward message gets dropped; then if Primary crashes, Backup misses that update.
Rule 2: Split Brain
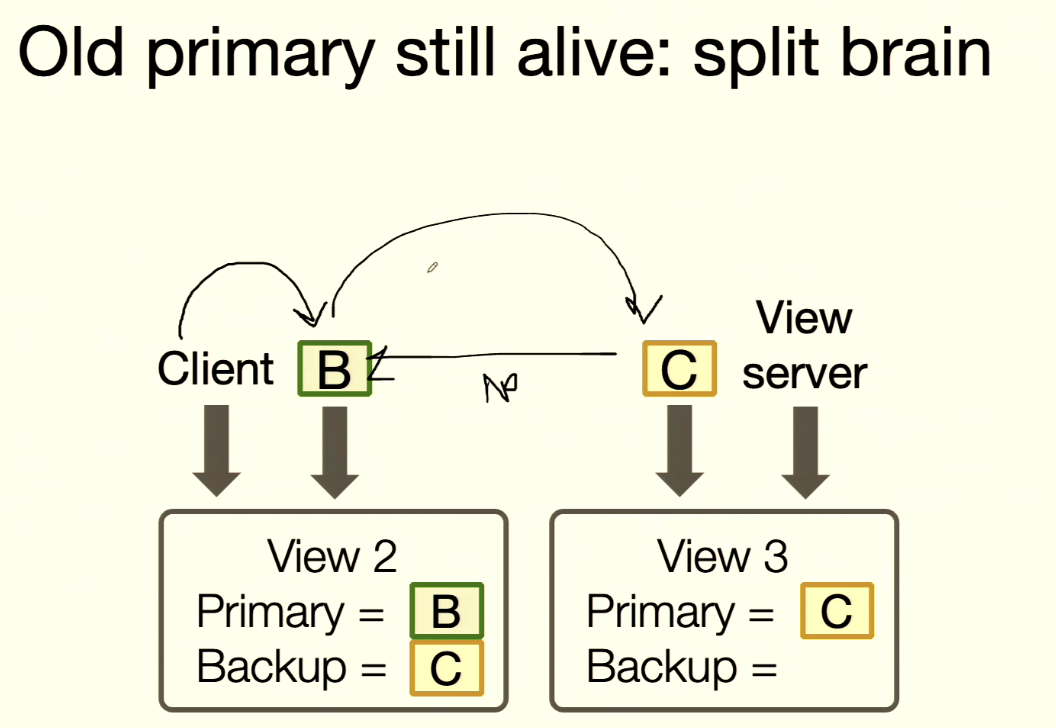
Rule 2 (Backup Check): Backup must accept forwarded requests only if view is correct.
- Server B is actually alive, but ViewServer has already created a new view and elected C as Primary.
- Client still thinks B is Primary and sends
putto B. B forwards to C (B still thinks C is Backup). - C receives forwarded request and sees
viewNum=2while its ownviewNum=3, so it rejects. - B times out, client times out, then client asks ViewServer for the latest view.
Rule 3: New Primary Must Have Been Primary or Backup
- Initially: Primary A, Backup B, and
putoperations execute. - A and B both crash; now Primary C, Backup D. A
getcannot read old data. - At startup in View 0 (no primary/backup), once any server pings ViewServer, ViewServer should immediately form View 1 and assign that server as Primary.
Rule 4: Non-Primary Reject Request
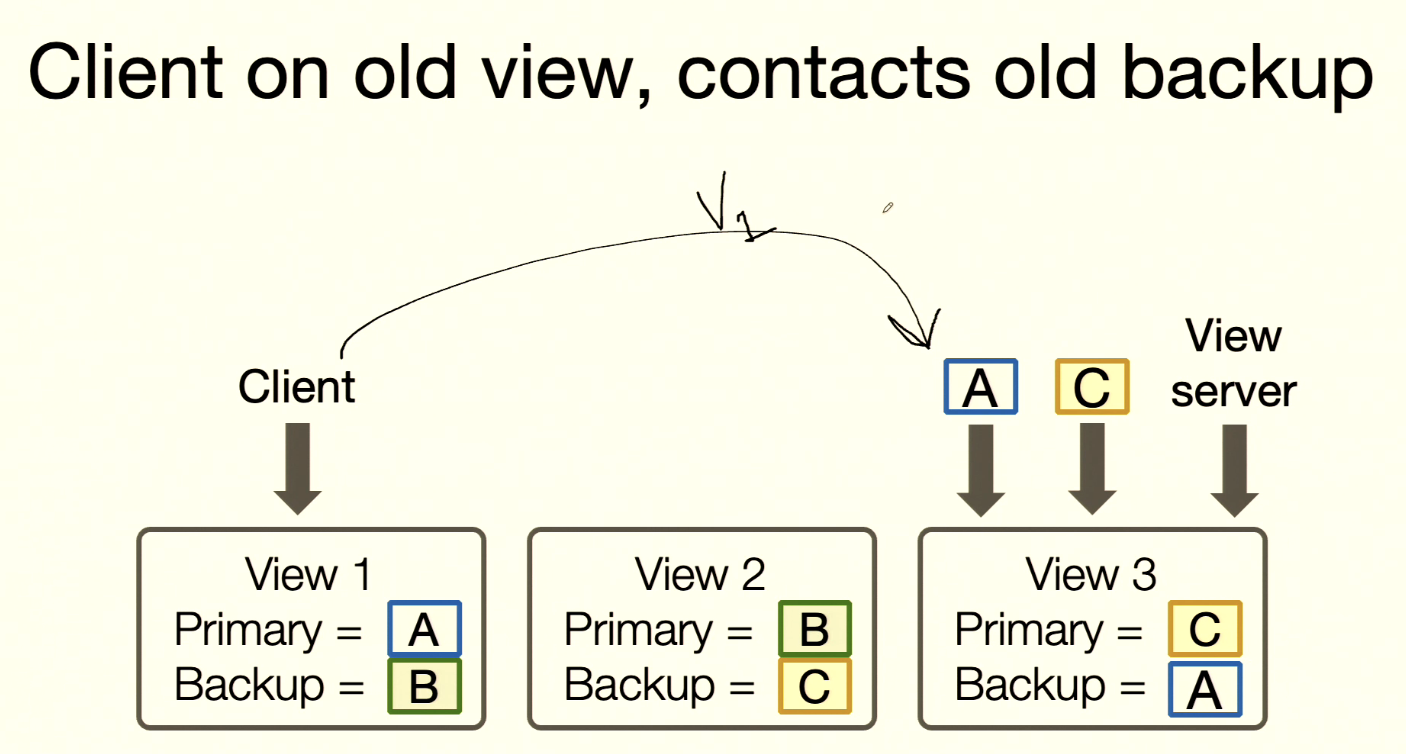
Rule 4: non-primary must reject client requests.
- A timed out before, then recovered.
- Client contacts A with
viewNum=1. - A knows its own
viewNum=3, so it rejects the request.
Details:
- On each request, a server must check whether it is Primary. If not, reject.
- First check if server ID matches current view’s Primary ID.
- Then check whether request
viewNummatches localviewNum.- If client
viewNum< localviewNum: common stale-client case. - If client
viewNum> localviewNum: server cannot be sure whether it is still Primary.
- If client
Rule 5: Primary Fail During State Transfer
Rule 5: ViewServer cannot change views until current primary has acked the view.
- A is selected as new Primary; ViewServer sends
viewNum=2. - A crashes before finishing state transfer to B, so A never sends
ping(viewNum=2). - ViewServer must not open View 3 (must not promote B to new Primary yet).
One way to do this: While A is still waiting for Backup ack, it keeps pinging ViewServer with
viewNum=1.
Another implementation requirement: We need to guarantee that state on backup is only overwritten once per view change.
Backup must record whether it has already finished initialization in the current view. Once done, it should reject/ignore later full-overwrite requests for that same view.
Because stateTransfer() messages may be delayed and client retries may happen, Backup might receive duplicate transfers. We must apply it only once.
stateTransfer(AMOApplication) sends the full current state once; Backup should record the last completed transfer view number and compare with incoming transfer view number before applying.
Rule 6: Atomic State Transfer
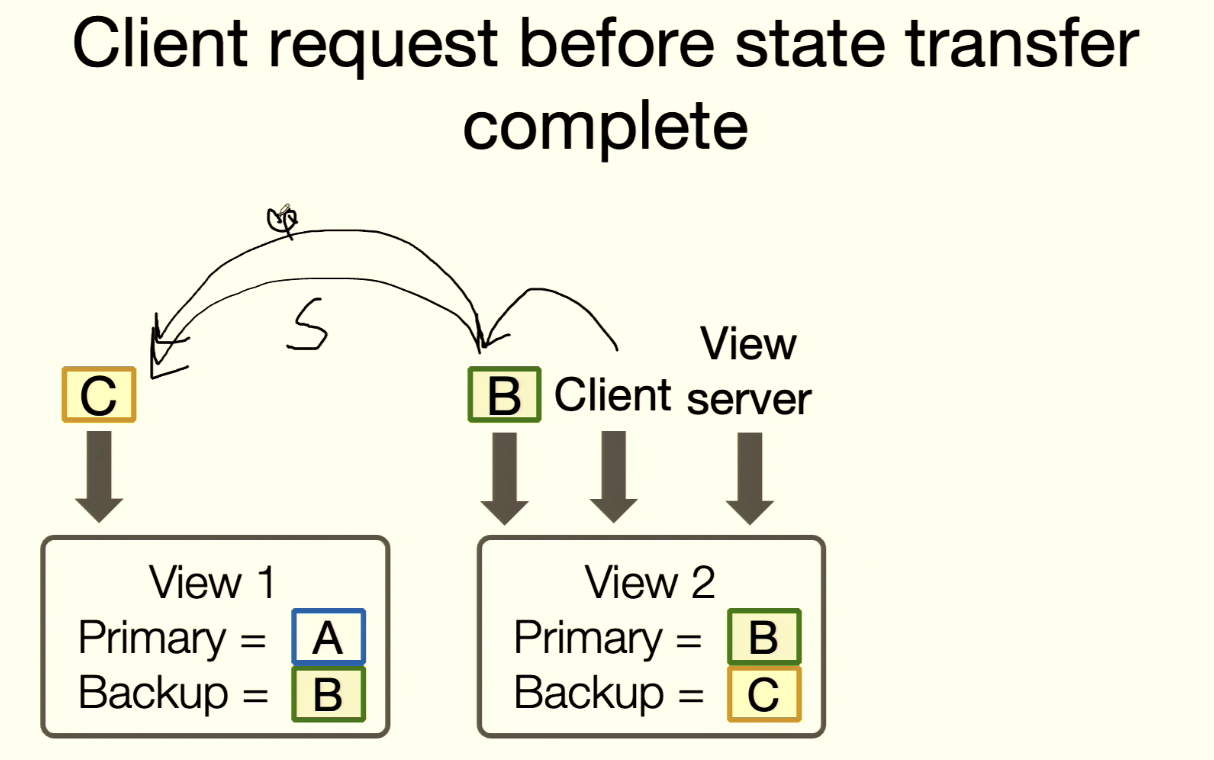
Rule 6: Every operation must be before or after state transfer.
- B is Primary and needs to sync state to C.
- Before sync completes, client sends request to B; B needs C to execute first, then B executes.
- But should C execute request first, or finish state transfer first?
- Solution: Primary should ignore client requests during state transfer. B waits for C’s transfer-complete ack before accepting client requests.
Paxos
Log Order
- The log has many slots; servers need to decide which operation goes into each slot.
- Each server proposes what operation should be placed in slot
i. - The proposal that gets enough votes is chosen for slot
i. - Losing operations retry in slot
i+1.
Terms
- Value: operation to be put into a slot.
- Proposal:
Tuple[Integer, Value]. - Accept: say yes to a proposal.
Roles
Each server plays all three roles:
- proposers
- acceptors
- learners
Phase 1: Prepare
- Proposer picks a globally unique, increasing proposal number (e.g., 8).
- Send to acceptors.
- Acceptor replies: promise not to accept proposals
< 8, and include previously accepted proposals (e.g.,[2,x],[4,y]).
Proposer only needs a majority of replies.
Phase 2: Accept
- If any acceptor reply already has accepted proposals, proposer must choose the value from the highest-numbered accepted proposal; otherwise proposer may choose any value (e.g., choose
yhere). - Proposer sends
accept(p, operation)(e.g.,(8, y)). - If an acceptor has not accepted anything with number >
p, it accepts. - If a majority of acceptors accept it, that proposal is chosen.
Liveness
- Some proposed value is eventually chosen: every slot eventually decides one proposal. So acceptors may accept multiple proposals over time, and eventually highest-numbered value wins.
- If a value is chosen, some process eventually learns it.
Safety
- Only a proposed value can be chosen.
- Only a single value can be chosen.
- A process never learns a value is chosen unless it was actually chosen.
Propositions
- p1: An acceptor must accept the first proposal that it receives.
- p2a: If proposal with value
vis chosen, every higher-numbered proposal accepted by any acceptor has valuev. - p2b: If value
vis chosen, then any later higher-numbered proposal issued by any proposer must also carryv. - p2c: In accept phase, if proposer wants to issue proposal number
n, it must first check whether any proposal< nhas been accepted by a majority. If yes, propose the value from the highest-numbered such proposal; otherwise propose any value.
In practice, we usually implement only p2c directly.
Learn Phase
- Once a value is chosen, acceptors inform a distinguished learner, who informs other learners.
- Learner leader is the proposer that proposed the chosen value.
Multi-Paxos
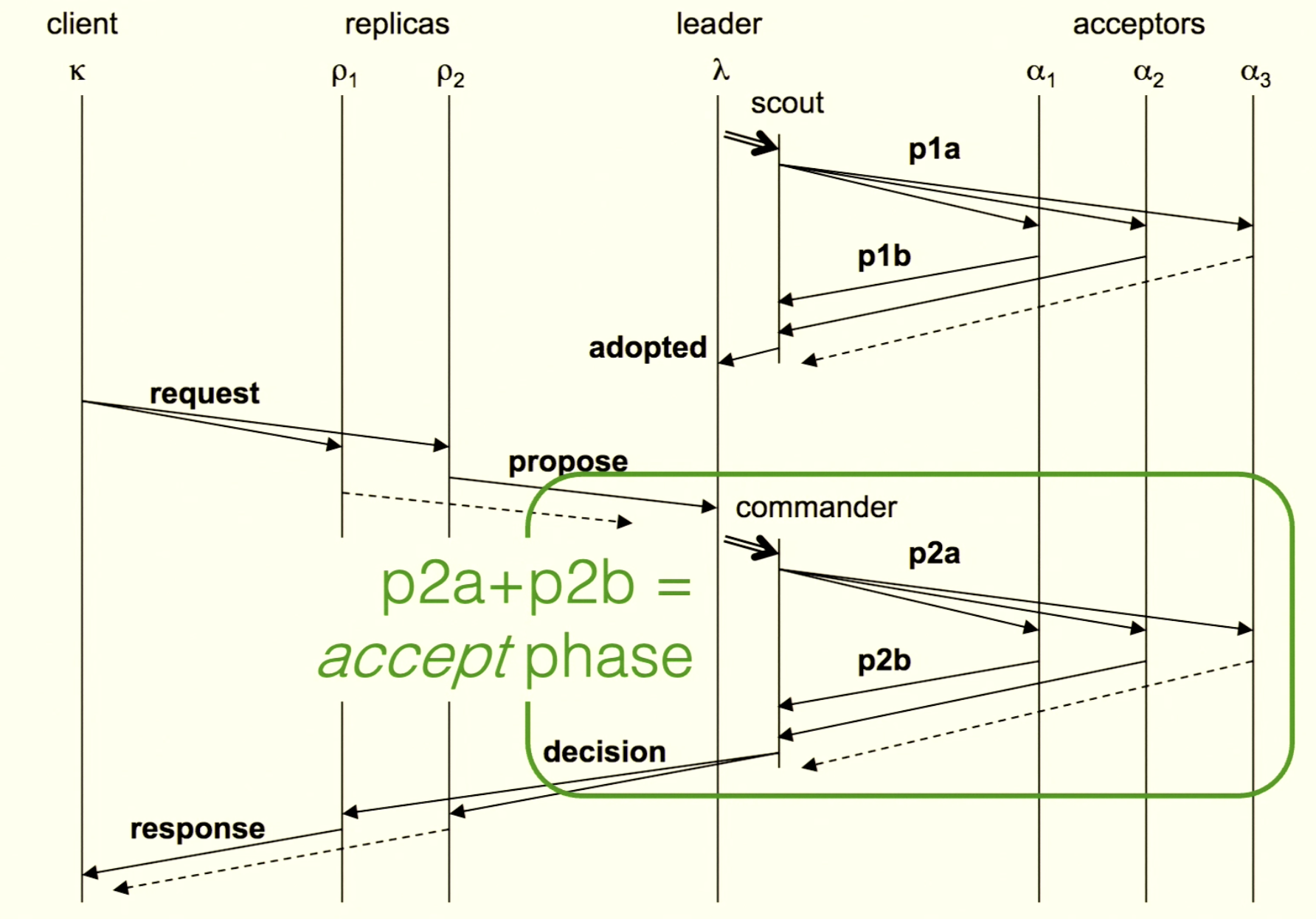
Ballot:
[Integer, ServerID]pvalue:
<Ballot, Slot, Command>Election phase: elect a leader, and its ballot is adopted by a majority of acceptors.
- Acceptor state:
- its adopted ballot (promise not to accept smaller ballots)
- a set of accepted pvalues
- p1a: leader sends ballot to acceptors
- p1b: acceptor replies with
all accepted pvalues + its ballot
- Acceptor state:
Proposal phase: leader proposes pvalues. If a majority accepts a pvalue, the slot is decided.
- p2a: leader sends pvalue to acceptor
- acceptor compares ballot; if matched, mark that slot accepted
- p2b: ballot + slot
- when leader receives p2b, compare ballot; if matched, mark that slot accepted by that acceptor
- p2a: leader sends pvalue to acceptor
Leader
Election starts when:
- system initializes
- current leader times out (heartbeat missing)
State:
active: true/falseballot_num: 0.0proposals: []seen:<1.2, 1, B>(a pvalue seen from p2b)
Election:
- send p1a to acceptors
- if majority accepted, set
active=true - otherwise choose a higher ballot and retry
- if majority accepted, set
- send p2a to acceptors
- if p2a is rejected, leader realizes it lost leadership; set
active=false, clear proposals - if accepted by majority, notify replicas
- if p2a is rejected, leader realizes it lost leadership; set
- send p1a to acceptors
If preempted, do not retry immediately [TODO: need specific design]
Heartbeat:
- ballot,
chosen{slot->command},first_non_cleared - leader sends heartbeat to acceptors; if ballot matches, acceptor can also mark those
chosenslots as accepted - if acceptor ballot is lower, it can catch up via heartbeat
- ballot,
On heartbeat timeout:
- others compete for new leader: everyone sends ballots; if a server receives a higher ballot, it becomes follower and treats that message as heartbeat from the new leader
Log
slot_out- next undecided/executable boundary
- all slots before
slot_out(1 toslot_out - 1) are already chosen and executed - increment
slot_outwhen something is executed
slot_in- next empty slot
- points to the next empty log slot for a new command
- when to increment: only when you are Active Leader and receive new client command
Log merging
- keep command with highest ballot
- if same command with same ballot is seen from a majority, mark as chosen
- no need to do this during p1b processing
- even if potential leader does not mark chosen now, once it becomes leader it can later discover chosen slots via p2a/p2b
- if no command exists for a slot, fill with
No-Op
Shadow log
- during Phase 1, do not merge p1b responses directly into main log
- use temporary structure (e.g.,
Map<Slot, Pvalue>) to keep best proposals - commit point: overwrite actual log only after election is won (majority achieved)
- abort: if election fails or preempted, discard temporary map
Log holes
- previous slot is empty while a later slot has value
- leader proposes
No-Opfor the empty slot - once chosen, application executes it (does nothing) and increments
slot_out
Garbage Collection
- Mechanism: heartbeat replies.
- Followers send their
slot_out(next command to execute) back to leader in heartbeat replies. - Leader computes
min(all_slot_outs). - Leader tells everyone: safe to clear logs up to
min_slot_out - 1. - Leader adds
first_non_clearedfield in heartbeat packets sent to followers.
Memory Consistency Models
Consistency
Consistency is a formal contract between programmers and system builders that defines allowed semantics and expected return values for operations on a data store. It specifies what behavior is allowed, not how it is implemented. So the system may use cache, replication, or sharding underneath without changing this contract. If a returned value violates the contract, that is an anomaly.
- Strong Consistency: system behaves as if there is exactly one centralized data store.
- Weak Consistency: broad category allowing behaviors that break the single-store illusion (e.g., stale reads).
- Eventual Consistency: a specific weak model; anomalies are allowed but temporary. If writes stop, everyone eventually sees same data.
Lamport’s Register Semantics
- Safe: read without concurrent write returns old value; read during write may return anything (even garbage).
- Regular: read during write returns either old or new value (not garbage).
- Atomic: regular + no going back. If one reader sees new value, all later readers must also see new value.
Linearizability
- No matter how many servers replicate in the background, to clients it behaves like a single machine: “write then immediate read sees latest value.”
- If A finishes before B starts, A must appear before B in system history.
- Single total order: all operations can be arranged into one linear global order.
- No stale read (lab3).
Sequential Consistency
- All operations follow one total order that respects each node’s local program order.
- Unlike linearizability, real-time order is not required; operations may appear “late” as long as everyone sees a consistent order.
- Allows stale reads (lab2).
- In database terms, often called serializability.
Causal Consistency
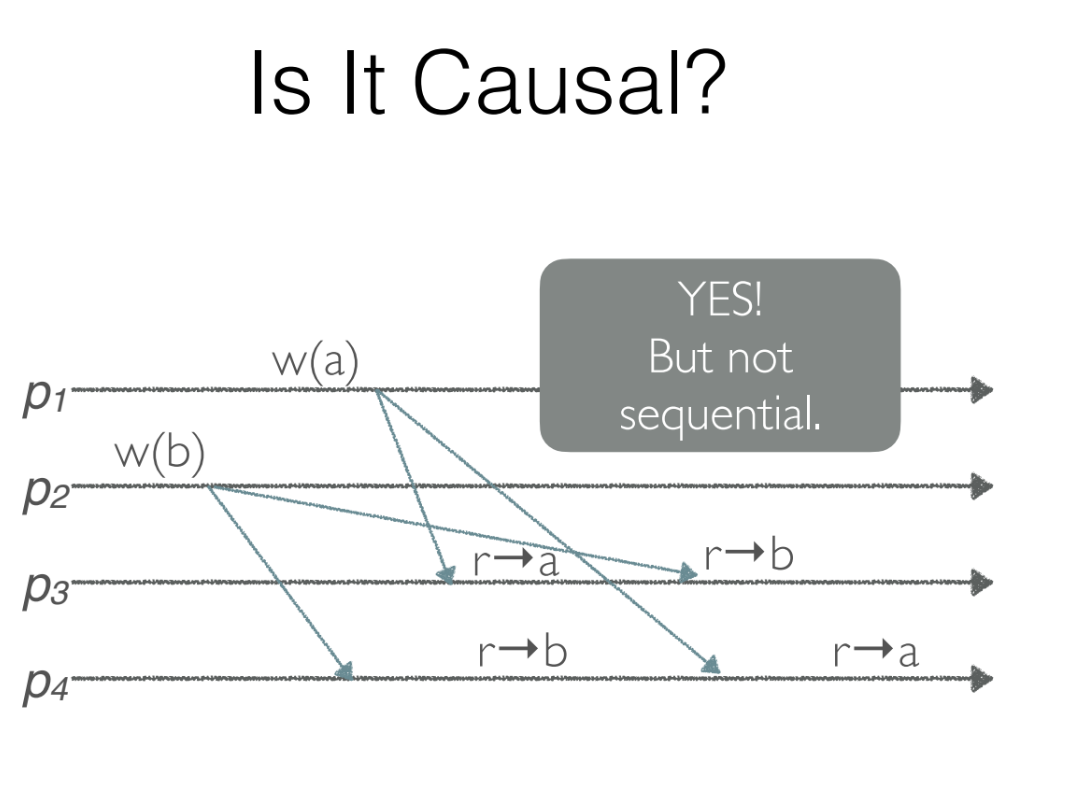
- No global total order.
- Maintain a happens-before DAG.
- Concurrent writes (independent writes) may be observed in different orders by different observers.
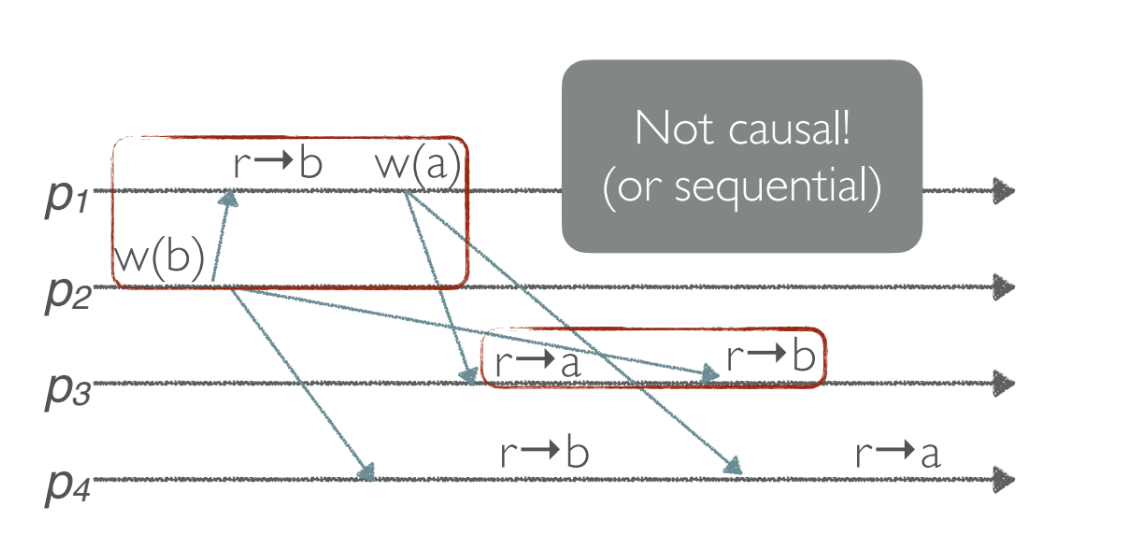
- Because p1 writes
aafter seeingb, - but p3 sees the effect before the cause.
Processor Consistency / Read-your-writes
- Writes by the same process are seen in order. If one process writes A then B, others must observe A before B.
- Writes from different processes may be observed in different orders by different readers.
- If a process writes a value, its subsequent reads of that value should observe that write.
Eventual Consistency
- If all writes stop, eventually all processes read the same value.
- Example: DNS.
Sharding
- Split key-value pairs into shards.
- Dynamically assign shards to Paxos groups.
- Need state transfer to move shards among Paxos groups.
- Minimize movement while keeping load balanced.
- Avoid deadlocks during shard movement.
- Clients maintain a table mapping shards to Paxos groups.
- Clients learn assignment from shard master.
Consistent Hashing
Place both servers and keys on a ring. If a new server joins, on average only K/N keys need to move.
- Treat hash space as a ring from
0to2^32. - Hash each server to a position on the ring.
- Hash each key to a position on the ring.
- A key belongs to the first server encountered clockwise.
Virtual Nodes
- Each physical machine is mapped to multiple virtual nodes on the ring, with coordinates like
hash(serverID + index). - For each key, walk clockwise to the first vnode.
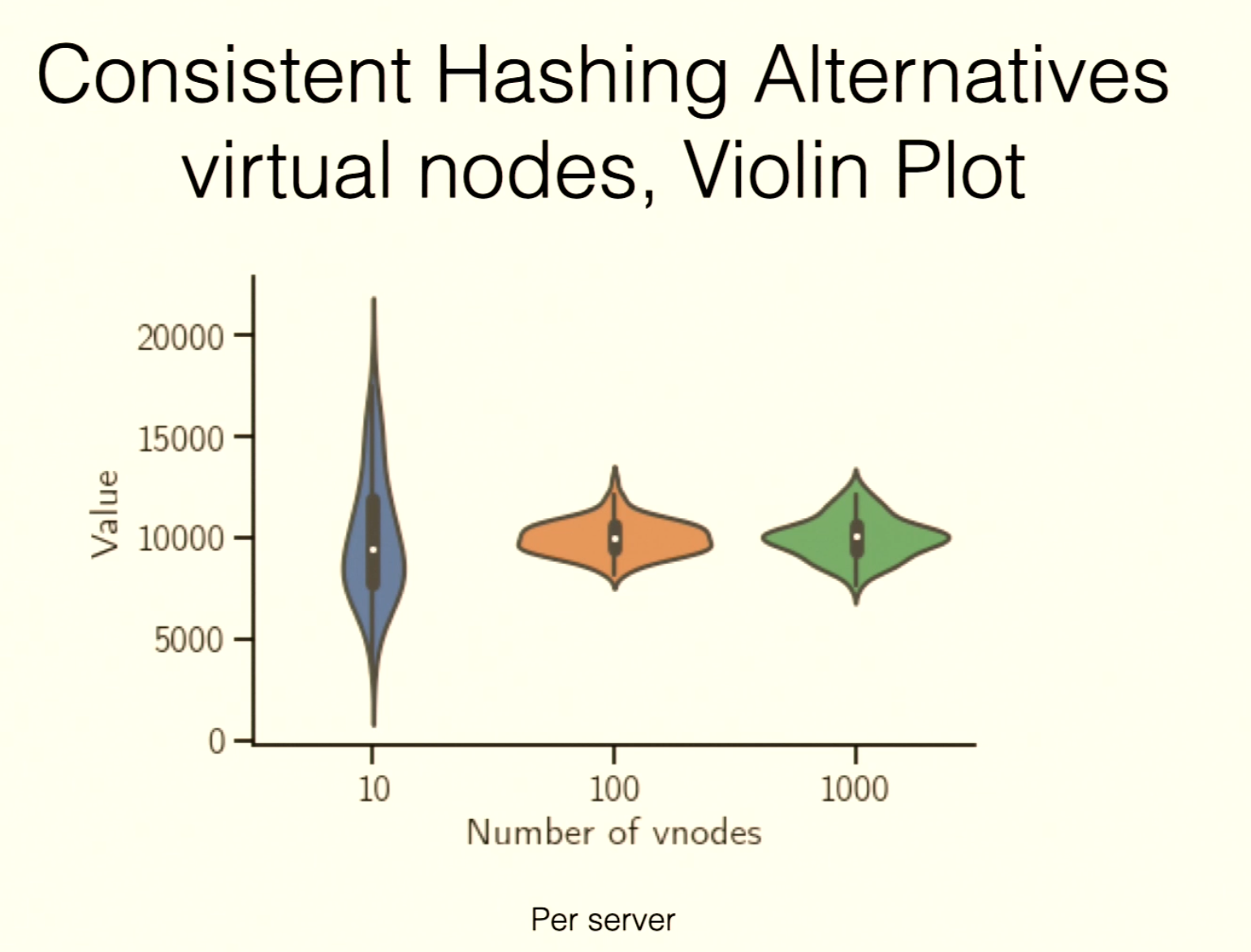
More vnodes means more even key distribution across physical machines.
Table Indirection
hash(key) = bucketserver = table[bucket]
Each client keeps the same table. Shard master adjusts bucket assignments in the table based on load, then broadcasts the new table.
This solves hot-key issues.
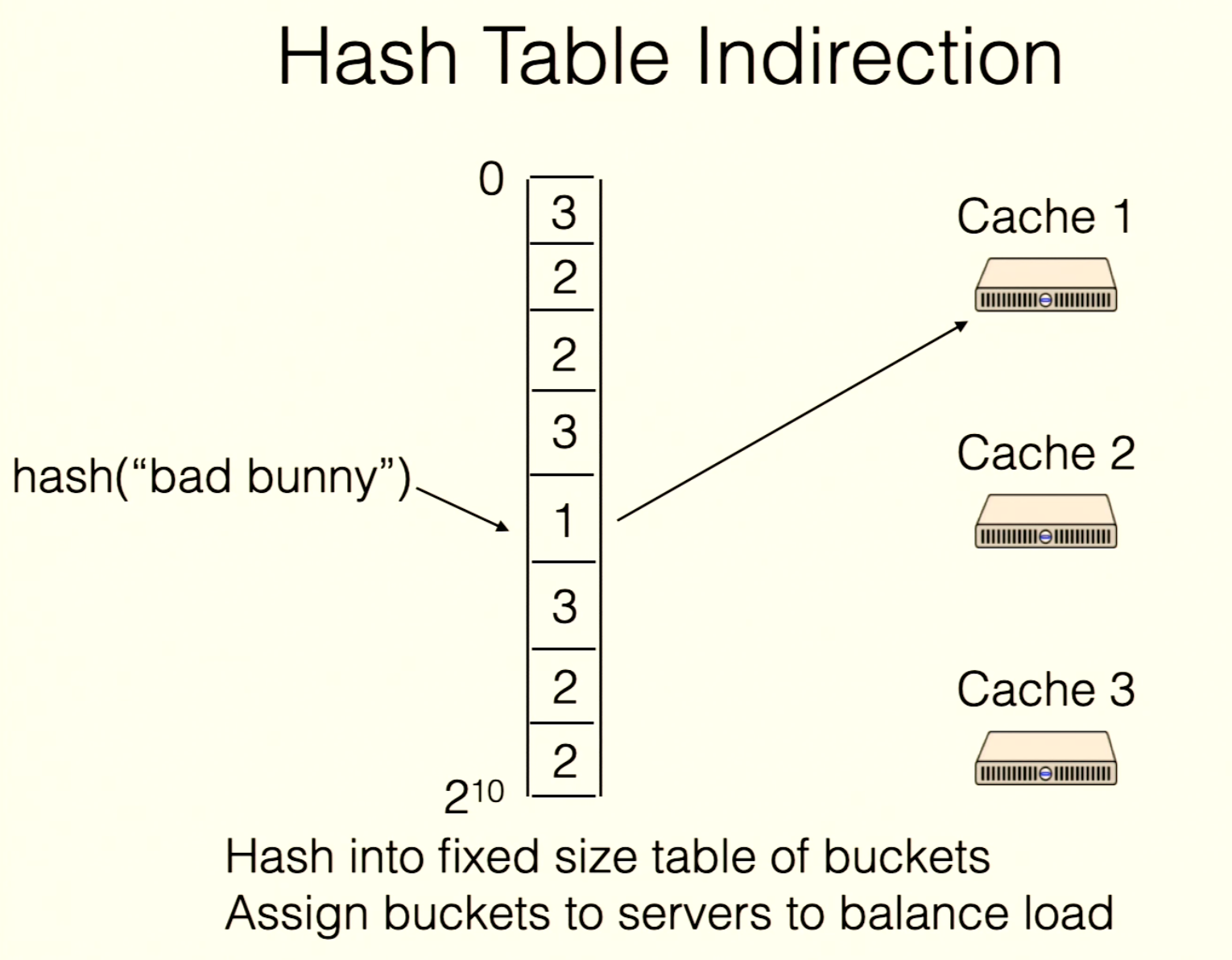 For example, if
For example, if bad bunny is a hot key, let server1 exclusively serve that bucket.
Goals achieved
- all clients share same assignment
- workload is evenly distributed
- adding/removing nodes moves only a few keys
- works even with hot keys
- redistribution work can be divided